
- français
- English
Time-aware Foursquare Venues Recommender
PROJECT: Time-aware Foursquare Venues Recommendation System
Motivation
Predict and suggest the trends of places in New York City according to the time and user’s availability. Filtering, aggregating and deeper analysis of data are activities that are planned to be conducted on the retrieved dataset from Foursquare API. This analysis is suitable to be done for a larger city like New York. Of course, the same process could be repeated for any other city in which the number of venues generated by the users is large enough.
Goals
1. Analyse the obtained data for the 4SQ venues over time.
2. Determine key available properties that can be used to provide both time and location-based recommendations.
3. Implement recommender that utilizes the aforementioned properties, and provides users with suggestions. This aspect, together with the goal from previous bullet, is the central point of the system.
Methods
Data would be obtained in the following way:
-
crawl venues located in New York City venues/search
-
for each of the venues also retrieve details venues/ID
-
obtain information about users that interacted with the venue users/id
We would use Spark as a data processing tool.
There are a couple of aspects of recommendation system:
-
Venue category, number of check-ins, likes, tips, rating etc.
-
Activity concerning the venues - number of checkins per hour, the busiest hours
-
Users that interacted with venues, and details concerning their overall activity on Foursquare, gender, from NY/US/outside
Important part of the project is the data analysis, and finding the right parameters that will deliver the best results. Aforementioned aspects of the recommendation system need to be thoroughly thought. Also, exploring the different types of the recommendation algorithms, and finding the one that is most suitable (and feasible) is crucial.
Finally, we would conduct the testing of the results provided by the recommendation system. This would be done by cross-matching the prediction with the already available data.
Milestone and organization
First, we will do the task distribution and the team setup. We will decide on which tools to use for every of these tasks.
Then, each team will stick to its task. However, we will also do some general meetings in order to see how the work is doing, if some teams need help, if everybody is aiming to the same direction. As soon as a team has some good results, they can start helping the others.
The tasks will have different schedules:
- One team will focus on acquiring of the data, so build a crawler for online streaming and setup the infrastructure. This has to be done quite early as it will be required by the other teams to test their algorithms (and their efficiency) on real datasets.
- One other team will focus on the recommender: they will analyse what already exists, improve it, and develop an efficient tool to recommend venues to the users’ criteria.
- If time allows, one or two persons will focus on implementing the visualization tools for the statistics of the venues and analysis of their trends.
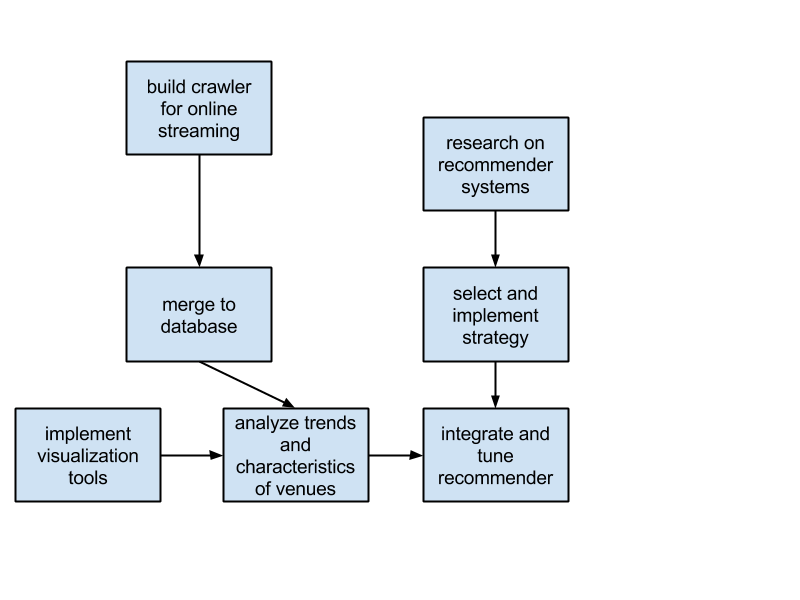
By dividing the workload in this manner, everyone will be familiar with all parts of the system, and if needed, they can provide their expertise. Also, we will save some time at the end for merging and testing purpose.
More detailed timeline is (more detailed task specification is available at the github repo):
-
Week 1 - finalizing the task delegation and proposal
-
Week 2, 3 - pulling data from Foursquare, learning about recommendation systems, making basic web UI
-
Week 4, 5 - persisting data, run Spark jobs to process data, implementing first version of venue classifier, add functionalities to web UI so users can provide input data
-
Week 6, 7 - work on recommendation system and predictions for the venue trends; extensive data analysis in order to produce the best results; exploring visualization tools if time allows, and using those tool to represent crucial aspects of the obtained data
-
Week 8, 9 - finalizing project, bug fixes and testing
Needed resources
- GitHub.
- Spark cluster.
- For storage, around ~20GB of space for New York City (that counts about half a million of venues), however we can reduce that number.
- Crawled data specifically for the city of New York., which is big enough to provides meaningful results.
- For visualization, we can use the tool mentioned by Mohammed El Seidy. Bar charts like this or that are interesting for trends.
Risk to the success
- Being able to get enough data about the relationship between users and venues is crucial, in order to make insightful statistics and predictions.
- We do not have experience in making efficient and meaningful recommendation system.
Team strength
- Experience in web development
- Scala, Java, Python
- Infrastructure experience
- Ready to learn Spark
- For the prediction: three students took a machine learning course.
- Large team comprehend different technologies and frameworks from a technical point of view, and different mindset can be helpful when trying to achieve some goal (the team includes different backgrounds/styles/nationalities and thus makes it easier to develop an app that suits many types of users).
Team members
-
Alexandru Ardelean
-
Julia Chatain
-
Emma Hesseborn Fagerholm
-
Ivan Gavrilovic
-
Bernard Maccari
-
Matteo Pagliardini
-
Boris Perovic
-
Tiziano Signo
-
Jakub Swiatkowski