
- français
- English
Titan Backend
Titan Backend for AiiDA
Introduction
Titan is a graph database running on 3 different backends:
-
Apache Cassandra
-
Apache HBase
-
Oracle BerkeleyDB

In the scope of this project we focused on a titan implementation with BerkleyDB (optimised for local usage) as the storage backend. For performance (indexing) we used ElasticSearch.
The aim was to investigate the local performance of querying the data in comparison with the current implemented Postgresql backend through the optimized Querytool.
In the current AiiDA implementation a Transitive Closure (TC) table is used to speed up performance for retrieving queries. This table stores every possible connection and depth of the connection for each node in a graph. As AiiDA’s graphs are relative small in size, this optimisation has worked up to now, but it already shows limitations on importing and exporting the data and requires a significant amount of Space to be stored.
We therefore decided to eliminate the TC table and use the graph query framework Gremlin for optimization.
The main advantage of moving to Titan as a backend would be to have a solution which works locally, but which could easily be expanded to work on a large cluster once enough data starts to be shared which was generated through AiiDA.
What we implemented
To be able to provide some benchmarking results between AiiDA’s postgresql backend and Titan we created and export script of existing AiiDA data. The created CSV files are afterwards imported through the Titan backend by a custom made script which also applies the following optimisation:
-
Ignores the TC table
-
Adds the attributes directly on the nodes it belongs to
-
Creates indexes on the properties we are benchmarking
-
Uses batch loading to improve the speed of importing the data
Once all the data is imported we run the benchmark script to compare the result with the AiiDA implementation.
Benchmark
The benchmark was executed on the same machine. We used the provided dockerfiles to have AiiDA as well as Titan run through a docker.
The following queries where used:
Q1 => Get all nodes with energy <= 0.0f
Q2 => Get all ndoes with energy > 0.0f
Q3 => Get all nodes with number_of_atoms > 3 and energy <= 0, from these get the input nodes 1 level up
Q4 => Get all nodes with number_of_atoms > 3 and energy <= 0, from these get the input nodes 1 level up and retrieve all attributes
Q5 => same as Q3 but 2 levels up instead of 1
Q6 => same as Q3 but 3 levels up instead of 1
We executed the equivalent queries from the query tool by using the Gremlin implementation.
Our first attempt generated random data which resulted in highly connected components which is in general not the case for the AiiDA data.
When generating the data we capped out the ID space of the TC table as the number of entries exceeded the MAX INT size (Table size ~300GB) and we needed to stop at 50’000 nodes.
With those 50’000 nodes we got the following results
Q1: time: 927 ms, size: 10181 nodes
Q2: time: 172 ms, size: 10155
Q3: time: 430637ms size: 42994
The queries on the AiiDA implementation needed to be aborted as after multiple hours they hadn’t finished.
This showed the limitation of the current AiiDA implementation if the data has largely connected components.
We therefore generated again random data through AiiDA but this time assured that the data where similar in the connectivity in components to the data currently used by AiiDA (small components of sparsely connected vertices)
In total we generated more than 1’000’000 nodes and imported them into Titan to run the queries with the following results:
For 100’000 nodes (only vertices indexed):

As we can see the results weren't really great for the graph databases. They yield in each case, except titan with berkley backend if all the attributes get retrieved, worse results than the current implementation. Important to note is the log scale! Queries which traverse the graph further become horribly slow on the graph database and are basically unusable.
Indexing is very important for graph databases. We therefore optimised the berkley backend for titan to also indexing the edges by adding a dummy property to the edge (titan requires to have at least one property to be able to index them). Indexing doesn't just allow to query edges on the indexed property but also stores the connection of the connected nodes.
After the indexing optimisation we managed to get to the following results:
For 100’000 nodes (vertices and edges indexed):
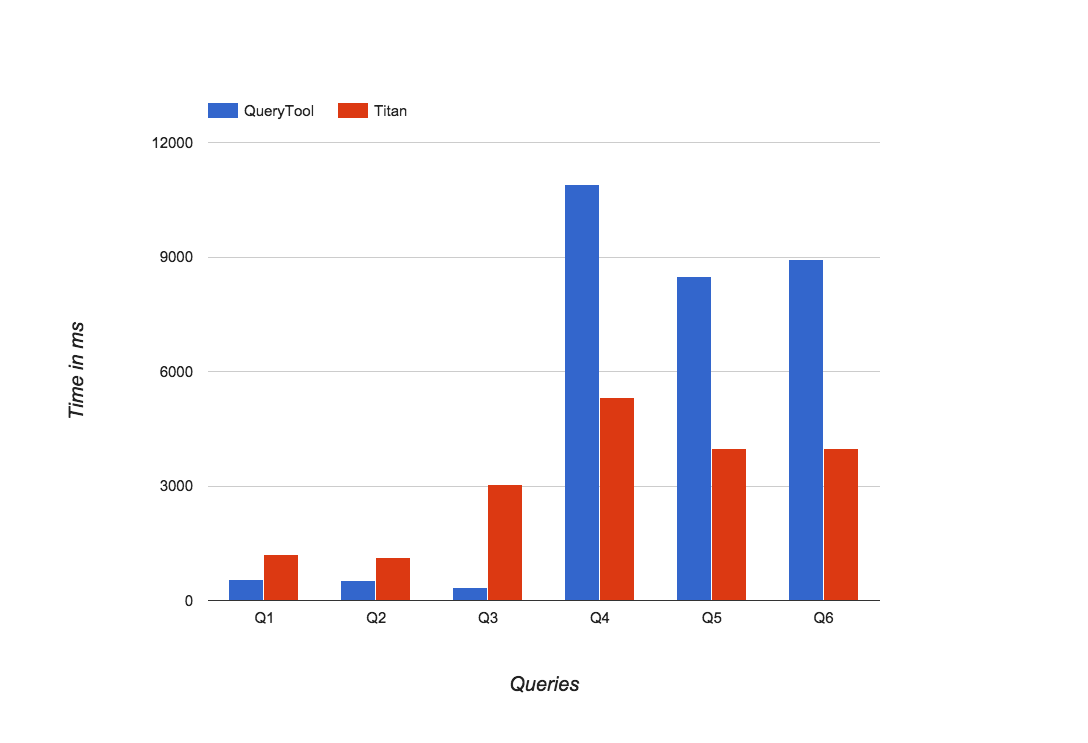
For 1’000’000 nodes(vertices and edges indexed):

Conclusion
As has been shown the local execution with Titan delivers better results than the current implementation of AiiDA unless only one vertex is retrieved (without any attributes). As soon as attributes are retrieved or the path is traversed titan becomes much more performant. To optimize the lookup through edges we need to add a dummy property on the edge to allow indexing on edges, as without any property edges can't be indexed by titan.
One of the main advantages of moving to a new backend would be to have a much simpler implementation and all of the desired functionalities of the query tool already implemented. We already discovered one wrong implementation in the old AiiDA query tool which could be detected due to the wrong number of results returned compared to titan. This is already an indicator that the current query tool will become harder and harder to maintain the more features will be added.
Using a third party framework which provides already all that functionality reduces the risk of incorrect returned results.
In addition the insertion of data, especially when batch imports are used, took only a fraction of the time compared to the current AiiDA implementation. This is mainly due to the fact that no transitive closure table needs to be built and mantained.
The main disadvantage is that there is no native implementation in the python language which is sufficiently stable only bulb which is still in heavy development and uses REST interface to communicate with the Titan backend.
Things to consider if Titan would be used
Array and Lists
Titan fully supports List and arrays but the current parser and importer doesn’t convert the Postgresql array row data into arrays yet.
User generated Attributes
The created attributes for nodes can be user defined, but in Titan the properties of nodes have a defined type (Int, String, Float etc.). A general naming schema needs to be defined to avoid property clashes of different types with the same property name.
One solution would be to incorporate the type into the property name (‘energy_float’) to avoid this issue. This becomes increasingly important the more data will get shared between users.
Indexes
In the current implementation of Titan, indexes need to be defined at creation time, before any node with the specified attribute exist.
There are two types of indexed:
-
Composite Index
-
Mixed Index
Composite indexes can only be used for `==` operations whereas Mixed Index can be used for inequalities and string searches. The main advantage of Composite Indexes is speed, but it needs to be chosen carefully as it can’t be altered afterwards (if an inequality might be used later)
During the import process not defined properties could be automatically indexes through the import script, but it potentially won’t be optimal as a mixed index would need to be chosen if not specified otherwise (as alone from the name it will be hard to infer which index to use).
Therefore a more elaborate importing script might be required in the future where such properties could be specified.
Still in heavy development
Titan as well as Gremlin are under heavy development. Many new features are added constantly and bugs are fixed. But there that also means that strange errors can be encountered and certain features might be missing (like the index generation after import, or using the copySplit operation in gremlin which leads to wrong results).
Overall we would still highly recommend to start implementing the Titan backend as an alternative to the current SQL based one. It will be much easier to maintain, provides better performance and allows AiiDA to be cluster ready just by changing a few lines of code.
Example Queries:
This section provides a quick overview on how the Titan database can be queried through the gremlin query language:
This simple query finds all the nodes which have more than 3 atoms and an energy greater than 0.
g.V.has('number_of_atoms', T.gt, 3).has('energy', T.gt, 0.0f)
A more complex version of the query before would be the followoing:
Retrieve all the input nodes to a node which has more than 3 atoms and an energy value bigger than 0 and retrieve all its attributes and remove duplicates.
g.V.has('number_of_atoms', T.gt, 3).has('energy', T.gt, 0.0f).in.map.dedup()
The following query will retrieve all the nodes which have an energy value greater or equal to 0 (labeled as start) and goes upwards the calculation graph up to 10 nodes to retrieve any node on the path which has either as an element Oxygen or an energy value lower than 0.
g.V.has('energy', T.gte,0.0f).node_label.as('start').
back(1).as('origin').
in().loop('origin')
{it.loops < 10}
{it.object.element == 'O' ||
(it.object.energy != null && it.object.energy < 0.0f) }.
dedup.ifThenElse{it.element != null}
{it.element}.as('element')
({it.energy}.as("energy").select
The following similar query gives a more precise result. It first find every node with energy greater than or equal to 0 and labels it as the ‘start’ node. it then loops backwards finding all the paths which have at least an input node with Oxgygen (element == ‘O’). From all these paths, it traverses the path again to retrieve now every node in that path with has an
energy value less than 0.
g.V.has('energy', T.gte, 0.0f).node_label.as('start')
.back(1).as('origin').in().
loop('origin'){it.loops < 10}{it.object.element == 'O'}.
node_label.as('element').
back(1).out().loop(1)
{it.loops < 10}{it.object.energy < 0.0f}.
node_label.as('energy').dedup.select