
- français
- English
Bigdata2015-hypercubejoins
This wiki page is about the Big Data course's project Hypercube Joins.
Hypercube Partitioning for n-way Joins
The goal:
To implement Hypercube Partitioning for n-way joins in Squall/Storm, a distributed online processing engine. In contrast to MapReduce which does batch processing, Squall/Storm [1] is designed for online processing.
Hypercube partitioning
At a high level, the join operator in a distributed setting consists mainly of two tasks:
a) partitioning data tuples among machines (reducers) and
b) performing the join locally on each reducer.
Partitioning schemes
Key partitioning: Traditionally, join processing in a distributed setting relies on key partitioning [2] of the data such that tuples from opposite relations with the same key eventually reside on the same machine. This technique works only for equi-joins. Furthermore, even in the case of equi-join, the load will be irregularly distributed amongst machines in the presence of data skew. In particular, a small number of machines processes most of the keys, whereas others are idle most of the time. This prevents load balancing and leads to very inefficient execution plans.
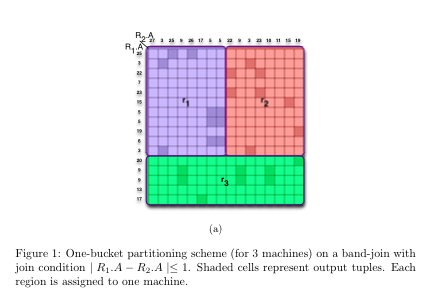
One-Bucket partitioning: An alternative partitioning scheme called one- bucket partitioning is proposed by Okcan et al. [3]. Instead of partitioning the input tuples by the join key, conceptually the output tuples are partitioned across machines. The output tuples are represented as cells in a matrix called a join matrix. Figure 1 illustrates a band join matrix between two relations R1 and R2, where the dark cells represents output tuples. We cover the matrix with rectangular regions, such that each output cell belongs to exactly one region, and each region is assigned a single machine. An incoming tuple is replicated among all the regions (machines) in a row or a column of a matrix. The objective is to minimize the input tuple replication. We made a short presentation of main concepts in the paper [4].
Hypercube partitioning: Hypercube partitioning is a generalization of the join matrix model from 2-way joins to n-way joins. Instead of matrices, we have hypercubes, which are divided into smaller hypercubes (instead of regions). Again, the objective is to minimize the input tuple replication size of each sub- hypercube (machine load). This is formalized and explained in Section 5.1 of Zhang’s paper [5]. In this paper, the authors are using Hilbert space filling curve
Our current team members:
- Guliyev Khayyam
- Gueniat Patrice
- Nguyen Thanh Tam
- Vu Minh Khue
- Wang Zisi
Supervisor:
Vitorovic Aleksandar
Deliverables and Task Assignment
-
Familiarize with Squall (1 week)
-
Implement the hypercube partitioning given the number of reducers (1 week) - Khayyam and Tam
-
– Evaluate the tradeoff between communication and computation: by trying different number of reducers (kr) for a hypercube join, validate the fact that there is an optimal kr.
-
– How it depends on the local join implementation?
-
-
Integrate it with Squall (1 week) - Khayyam and Tam
-
Local indexes for more efficient execution of equi-joins, band-joins and inequality joins in Squall (1 week) - Patrice
-
Experiments & Identify TPC-H [6] queries which could be executed with- out any communication among the machines of the same operator. Some of the nested queries certainly does not qualify. (3 weeks) - Khue and Zisi
-
Set up Squall/Storm in Microsoft Azure images, with a tutorial
-
Identify TPC-H [6] queries which could be executed without any communication among the machines of the same operator. Some of the nested queries certainly does not qualify. For each TPC-H query that requires communication among the machines of the same operator, precisely explain what needs to be communicated and between which machines.
-
evaluate the performance of a n-way hypercube-join (n = 3, 4) versus the corresponding pipeline of 2-way one-bucket joins.
-
What is the effect of the total number of tuples sent over the network (including the intermediate stages) on the total execution time?
-
How it depends on the local join implementation (SquallToaster, HashIndexes, Balanced Binary Tree)?
-
- Writeup (1 week) - All
Note that the assignment is tentatively. We can change during the semester based on the actual work load.
References
[1] “Squall: A distributed online processing system.” https://github.com/ epfldata/squall.
[2] “Mapreduce/mapreduce relational join in the coursera course introduction to data science.” https://class.coursera.org/datasci-001/lecture/ preview.
[3] A. Okcan and M. Riedewald, “Processing theta-joins using mapreduce,” SIGMOD 2011.
[4] “Theta-joins on mapreduce.” https://www.youtube.com/watch?feature= player_detailpage&v=x4R2hbkA5Ik.
[5] X. Zhang, L. Chen, and M. Wang, “Efficient multi-way theta-join processing using mapreduce,” in VLDB, 2012.
[6] “The TPC-H benchmark.” http://www.tpc.org/tpch/.
[7] “Squall local mode.” https://github.com/epfldata/squall/wiki/
Quick-Start:-Local-Mode.
[8] S. Chaudhuri and V. Narasayya, “TPC-D data generation with skew.”